〇バーチャルヒューマンのゴール
コンピュータ上で構成されるバーチャルヒューマンの最終的なゴールは、リアルに見え、現実同様に動き、アニメーションさせるボーンを持ちシンプルで数学的に体の形を定義したモデルです。

SMPLはこれを目標に構築されているそうです。
また、あらゆるソフトで使えるように一般的なグラフィックツールに適応するようにする必要があります。
データにフィットさせるというのはモーションキャプチャにおいて最も重要なインプットに対してバーチャルヒューマンを合わせることを指します。
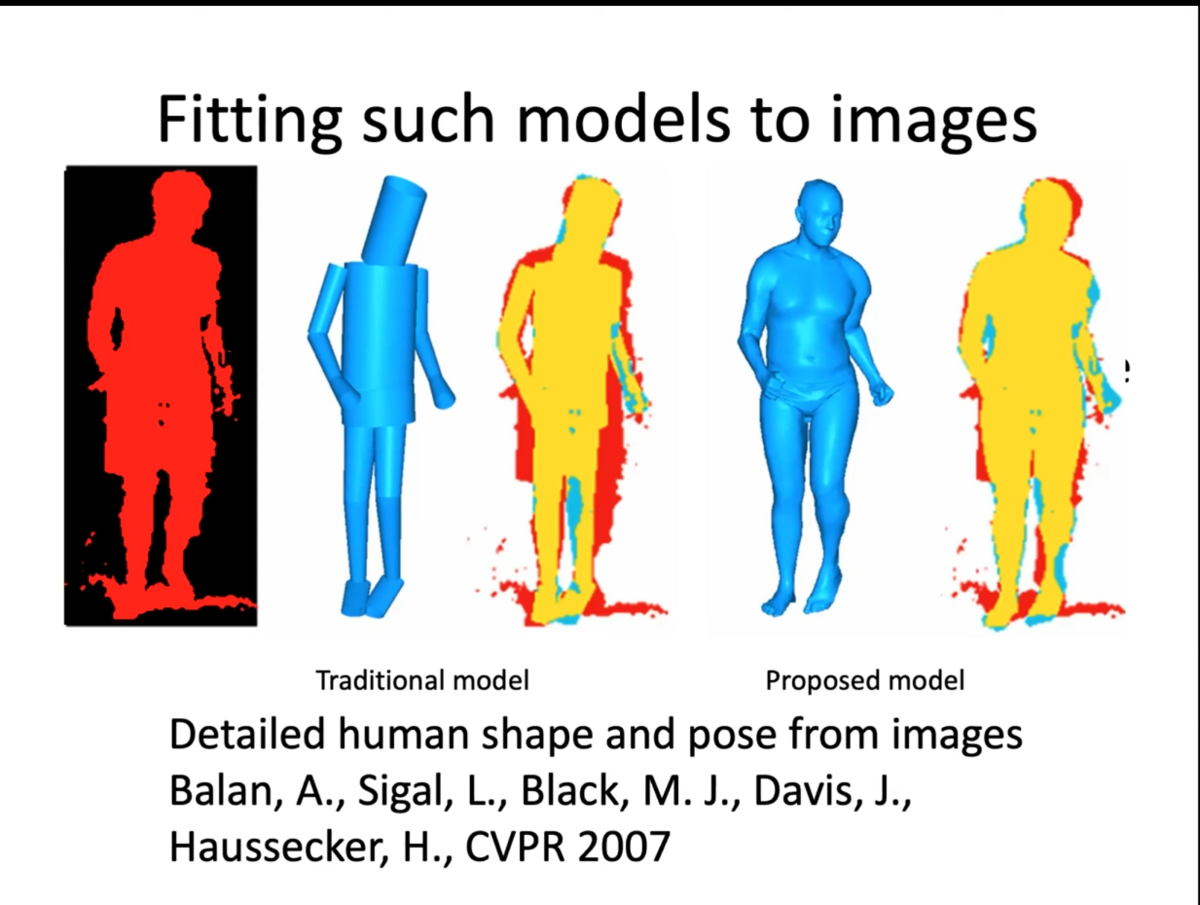
この時に使用されるデータはRGBD(色+Depth)の画像なり、モーションキャプチャマーカーの可能性もあります。
このためデータに適応するようにバーチャルヒューマンは微分可能(Differentiable=モデルが入力データの微小な変化に対して滑らかに反応すること)である必要があります。
〇学習のためのスキャンデータ
2000年前後はCyberwareのスキャナが主流でした。
しかしスキャナは撮影に12秒かかるうえlaserスキャンのため目を閉じる必要があり、複雑なポーズでの撮影を困難としました。(目を閉じたまま複雑なポーズを12秒維持するのが大変だった)

SMPL著者のMichaelさんがマックスプランクインテリジェンス研究所に参加した際にまずこのスキャナを探し回って、新たに構築できる企業を見つけました。
3dMDがMichaelさんの仕様を実現できると構築したようです。

このスキャナは空間内で飛び回り、腕を自由に回せる広さで60fpsでスキャンできる性能だそうです。

66台のカメラがあり、22台がテクスチャをとるためのカラーカメラであるようです。
これによって今までよりも精度の高いデータをとることができるようになりました。

〇SMPLモデルのモデリング
スキャンの仕組みができたところで次にデータのキャプチャを行う際にはCAESAR datasetを使用して、1000の高解像度スキャンデータとポーズをスキャンしました。
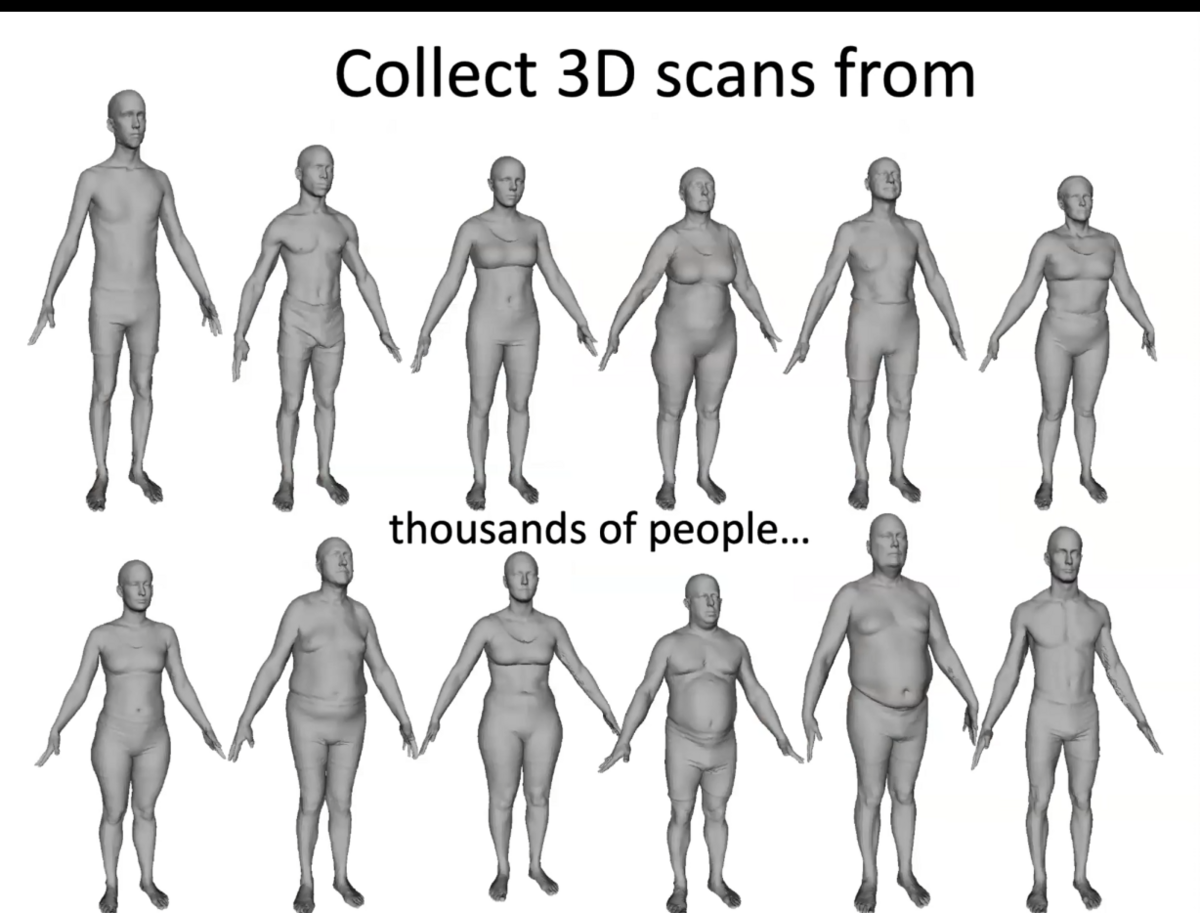
これを使用してパラメータを学習させます。
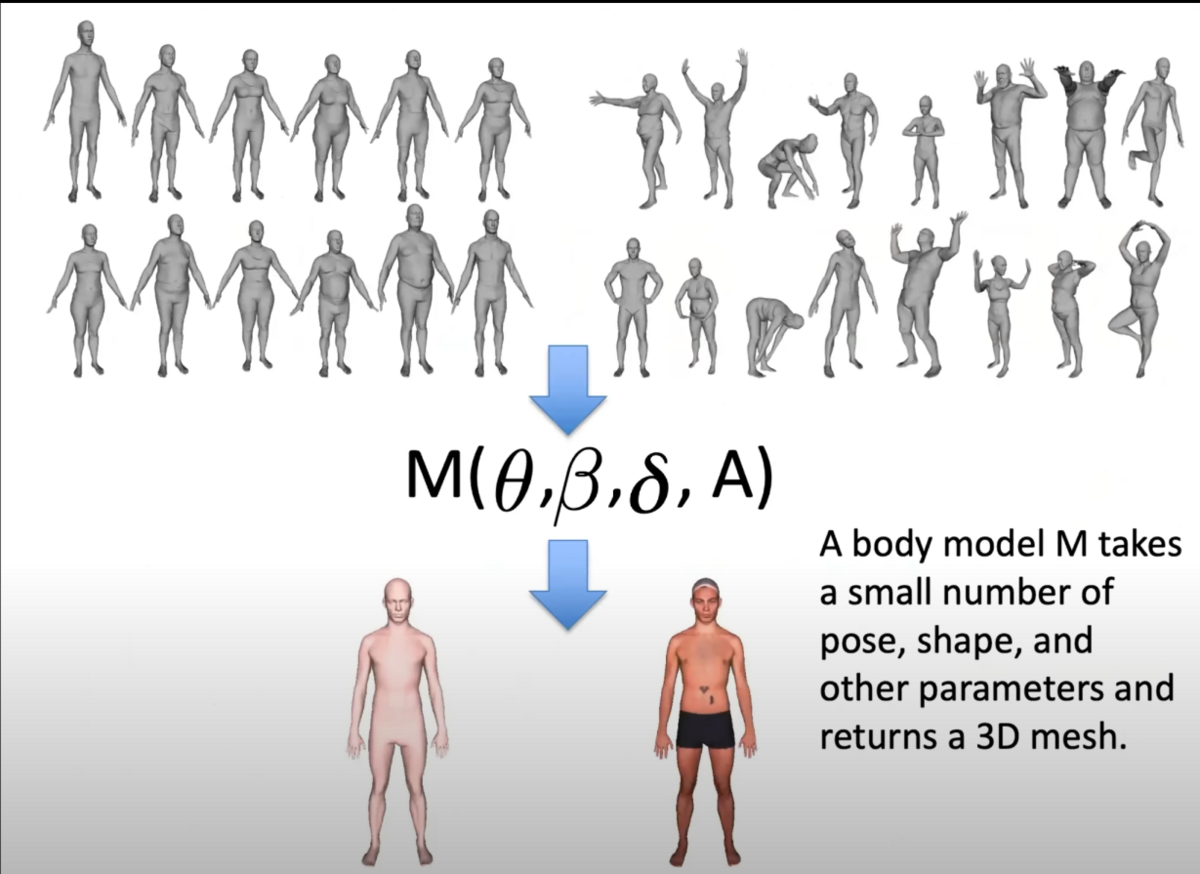
ここでモデル形状ですが、男女で同一のメッシュ構造を持つように設計されています。
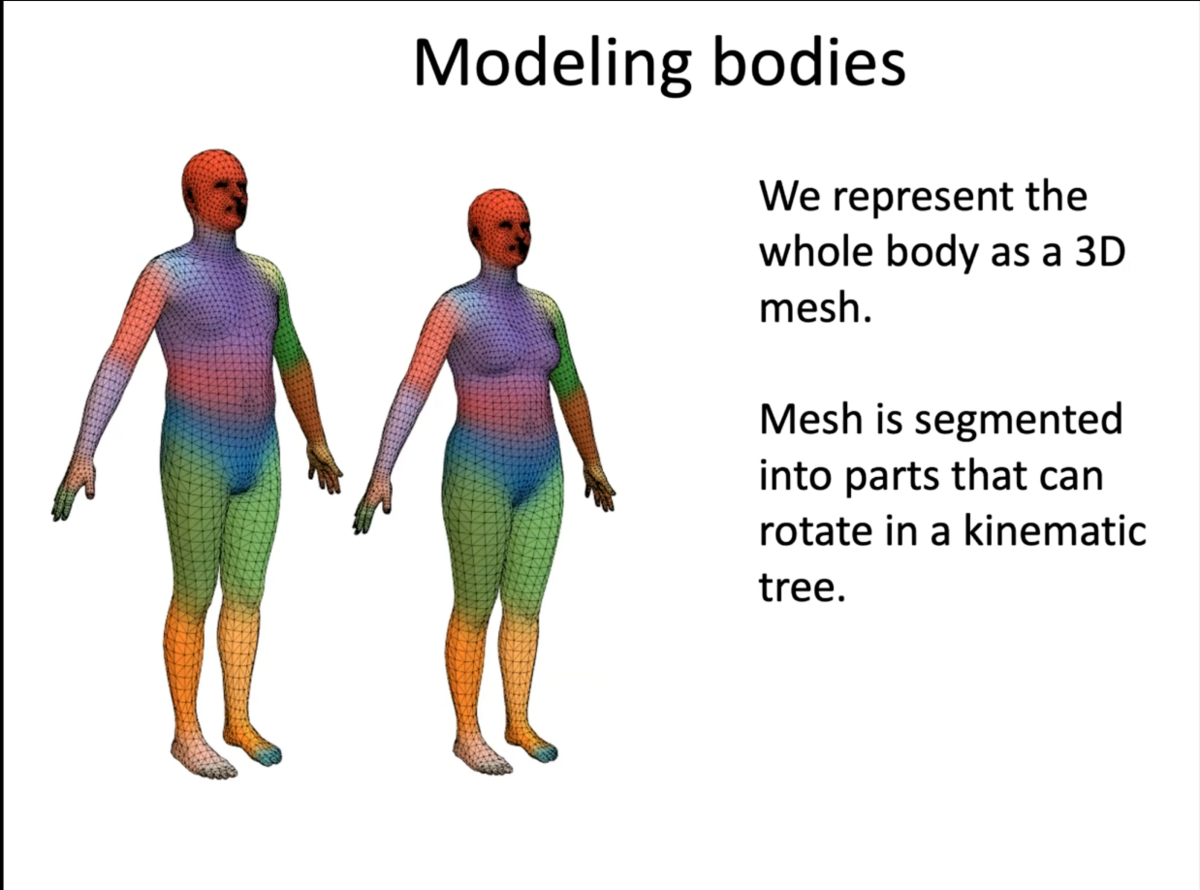
ジェンダーニュートラルなトポロジーになるように作成し、これを実際に作成するのは生身の人間であり、ここに多くの試行錯誤があったようです。
最初期は7000の頂点、21000のパラメータで構成されており、このパラメータによってスキャンデータのどの設定が対応するかを特徴づけるようにしました。
これを行うための関数を学習させています。
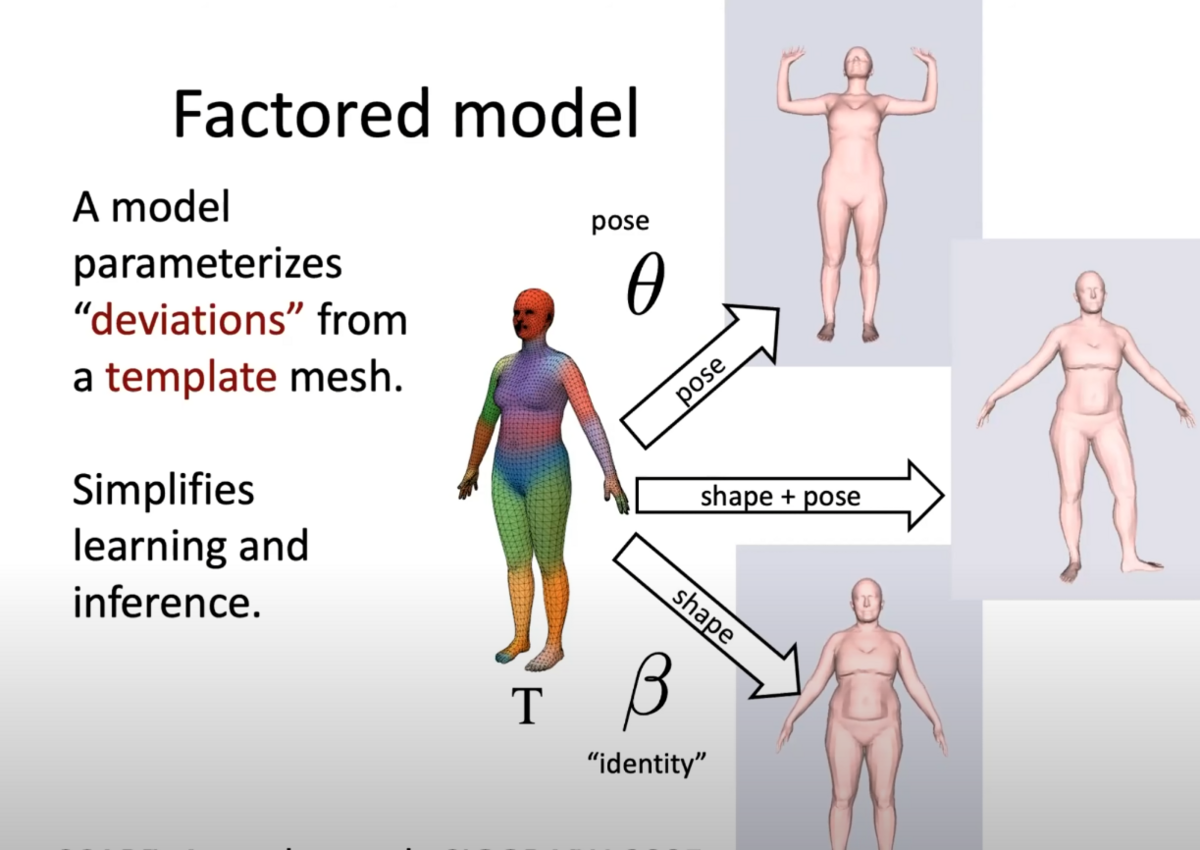
ポーズ・シェイプ(形状)二つのモデルからパラメータを割り出すことでポーズを変える動作が同一人物に見えるようになります。(見た目的にシェイプが破断しないようにアニメーションする)
これによって例えば息の動作や、きめ細かな動きなどスキャンしていない新しい動きもできるようになりました。
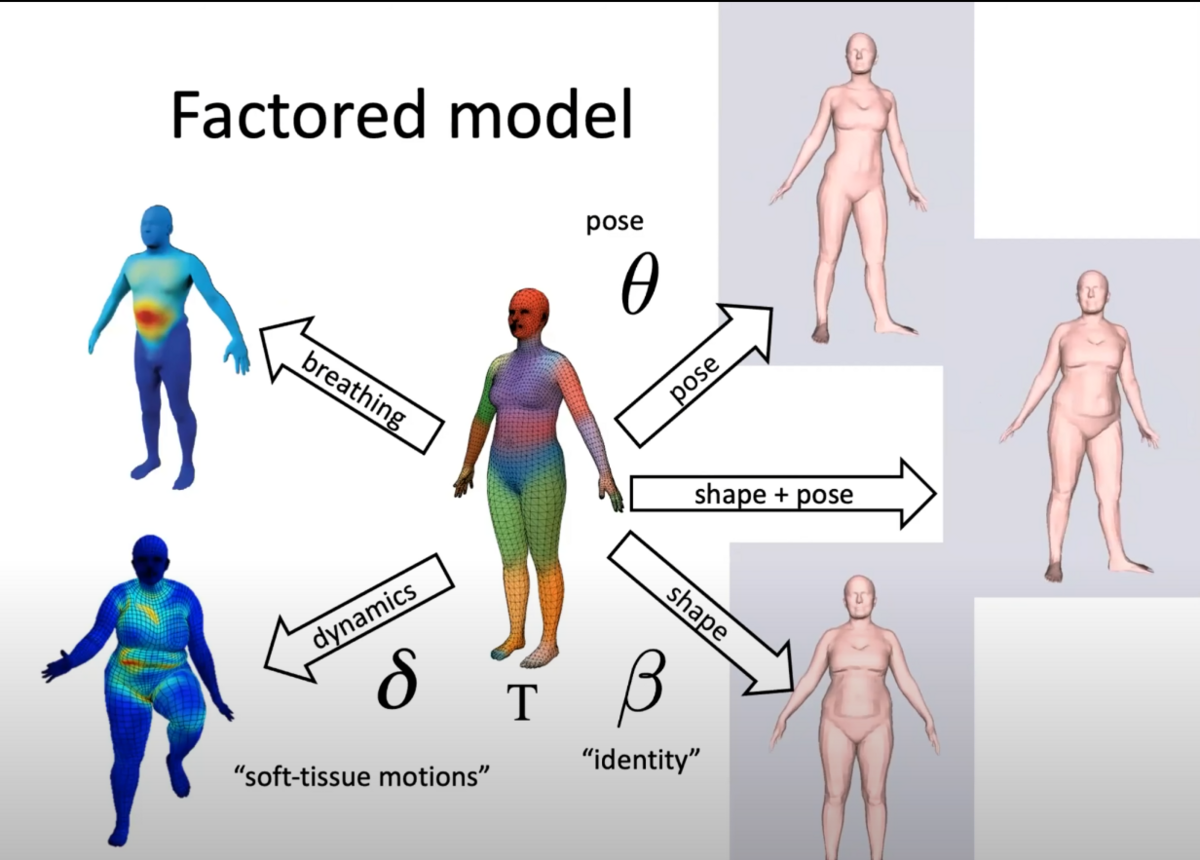
この原理は後にSMPLにつながるScapeの基盤となっています。