本日は昨日に続きSMPLについて著者のMichael BlackさんのYoutubeビデオを見ながら理解を深めていきます。
前回はモーションキャプチャの歴史を受けてスキャンの方法についての紹介を読んでいきました。
今回はそうして取得されたスキャンデータの問題点と解消を読み解いていきます。
〇スキャンの問題 点群からモデルデータへ
3Dスキャナによるデータの問題としてスキャンデータはモデルではなくただの点群の集まりにすぎません。

ここからモデルとして構築する必要があります。
この方法としてテンプレートメッシュにスキャンデータを合わせる(マッチさせる)という手法がとられます。

最初にスキャンしたデータに合うようにテンプレートメッシュを変形させポーズをつけてスキャンデータと重ねているようです。この作業のことをアライメントと呼びます。

これが難しい理由はいくつかありますが、これはテンプレートメッシュ(上画像でのピンク)とスキャンデータの解像度の違いです。

二つ目は実際の人体の表面は滑らかな部分が多く特徴を捉えることが難しい点です。
例えば、ある人物と別の人物の性格に一致する特徴点はどこなのか?ということは非常に定義がしづらいです。
そして何より実際の測定データには欠落が発生する可能性があるということで、例えば脇やひざといった部分はスキャンする際にポーズによってスキャナで胴体と区別できず認識できないことがあります。
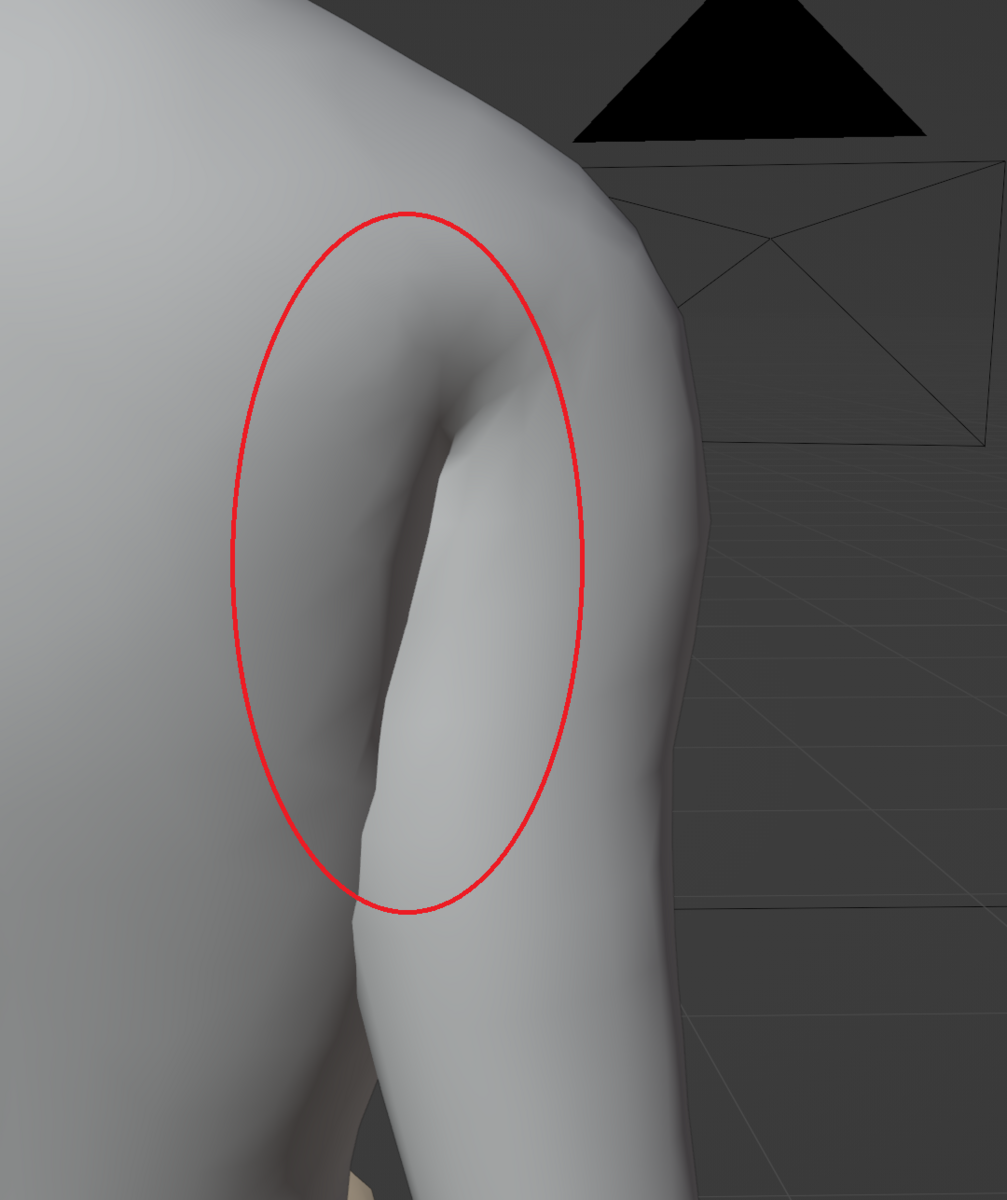
このようにデータの欠落が見られるとさらにテンプレートと合わせてパラメータを求めることが困難ですがSMPLモデルの研究に当たりCo-registration(共同登録≒重ね合わせ)という手法を使用したようです。
〇Co-registration
正確な欠落のないスキャンデータがあればデータに合わせてテンプレートモデルを使用して形状(体格)とポーズを洗い出せます。
しかしそのデータを得る段階でアライメントが必要であり、卵と鶏の問題になっていました。


データとテンプレートをそれぞれ別の問題として考えるのではなく、データとテンプレートモデルを一緒に登録することで解消させる手法がとられた。
最適なテンプレートモデルを生み出すために元データに重ね合わせるます。

The FAUST datasetではこれらの手法を用いて作成されたデータを見ることができます。
ここまでがスキャンの方法とスキャンの問題、そしてその解決でした。
次回は最適化の方法を読んでいきます。