本日はAI枠です。
現在SMPLモデルを読み解いています。
このあたりから考え方など難しくなるのでしっかり読み解いていきたいです。
SMPLについて著者のMichael BlackさんのYoutubeビデオを見ながら理解を深めていきます。
〇スキャンデータとテンプレート化の問題
SMPLモデルを構築するためにスキャンデータを使用していました。
2000年前後に搭乗した米国国勢調査に基づくデータCAESAR dataseのスキャンデータではいくつかの問題がありました。
例えば特定の下着のみのデータであることや、子供のデータがないこと、服に関してもほぼ下着姿で撮られたデータで現実世界の人間との差異がありました。
子供は大人と体格が大きく異なります。

人間の多様性をとらえるという意味では、体脂肪を例にとることで考えることができます。
太って体に脂肪がついた場合、足につくのか、腰につくのか、腹につくのかは人によって大きく異なってきます。
ここで、人間にはとてつもない量のパラメータが存在することがわかります。
〇同一ポーズのテンプレートメッシュ
形状のトレーニングセットとしてテンプレートメッシュが必要ですが、これはCAESAR datasetをもとに性別ごとに2000のメッシュを同じポーズに正規化を行って作成しました。

ここで重要な点が大体一緒のポーズではなく厳密に同じポーズであることが重要です。
これは前述のデータセットの問題や個々の人間の特徴を抑えて学習を行う上で重要なためです。
性別ごとの同じポーズの異なる体格のデータから人間の形状を統計学で得ることができます。

最初に取得できるデータは上記図の身長と体格(体重)です。
次に体の各部21000点をパラメータとして体格をパラメータ化しなければならないのですが、21000点は定量化するには値として大きすぎます。
このため次元を落とす必要があります。
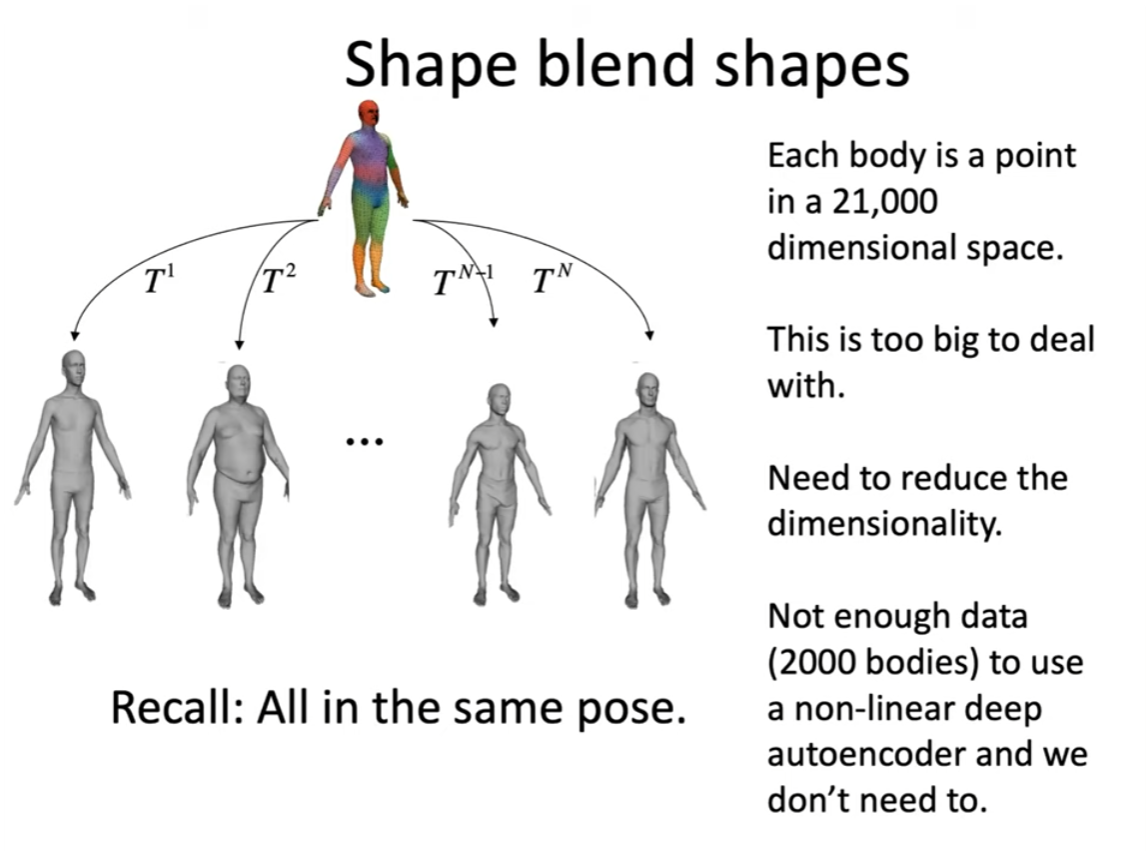
同一ポーズのテンプレートメッシュを使用して頂点ごとにメッシュのベクトルを持たせます。
このメッシュの平均値をとることで特徴部をパラメータとすることができます。

このようにして頂点ごとのベクトルの平均をとることでBlendShapeとしてモデルを構築することができました。
本日は以上です。