本日は昨日に引き続きStable Diffusionを導入していきます。
昨日は公式のリポジトリからCloneしてPythonの環境構築までを行いました。
本日は学習モデルを用意して実行までを行います。
〇学習モデルの用意
Huggingfaceを使用して学習モデルを用意します。
①サイトへアクセスをします。
②初めて使用する場合はsign-upを行う必要があります。

③次のリンクからStable diffusionの学習モデルを入手します。
入手するモデルはFiles and versionsにあります。

この中のsd-v1-4.ckpt を使用していきます。
④Downloadボタンを押しダウンロードを行います。
⑤ダウンロードしたモデルデータを昨日構築したStable Diffusionのmodels\ldm\stable-diffusion-v1に配置します。

⑥ダウンロードしたモデルのckptファイルの名前をmodel.ckptへと変えます。

⑦Pytonのコマンドを実行します。
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
処理が始まります。

処理が完了するとEnjoy.のメッセージが表示されます。

⑧処理が完了するとoutputフォルダに生成された画像が格納されます。
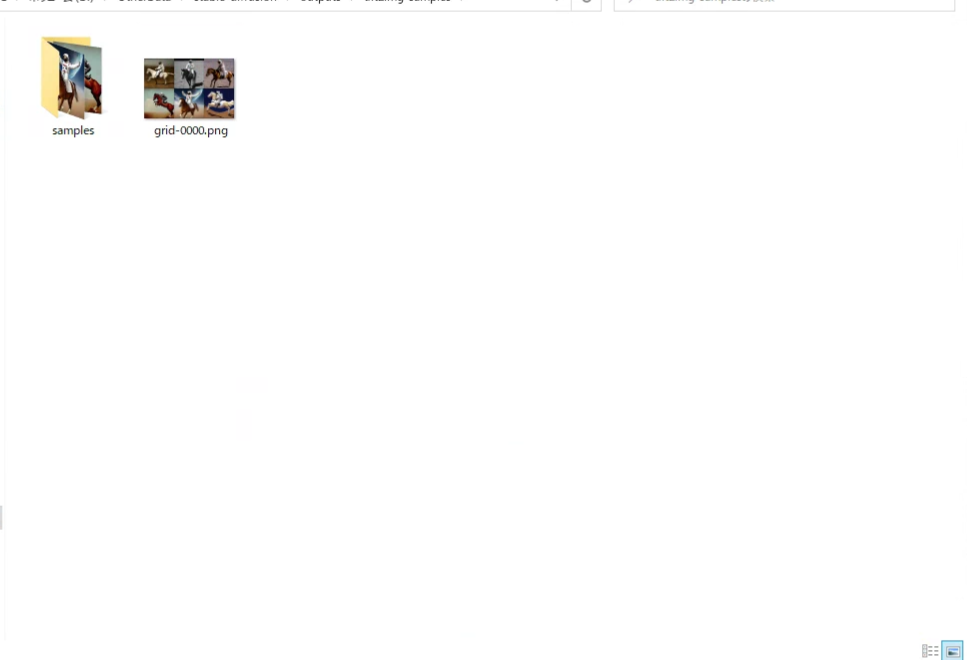
乗馬する宇宙飛行士の画像が作成されました。

今回は実行するコマンドにpython scripts/txt2img.py --promptの後にa photograph of an astronaut riding a horse(乗馬する宇宙飛行士)とつけていたので正しく画像が生成されたことがわかります。
以上でStable diffusionを動かすことに成功しました。
ここからは実行するメッセージを変えることで任意の画像を作成できます。
〇An angel descending from the sky(舞い降りる天使)

〇Sukiyaki(すき焼き)

〇A person cutting vegetables with a lightsaber(ライトセーバーで野菜を切る人)

以上で自由自裁にStable Diffusionで画像生成ができるようになりました。
本日は以上です。